26 maart 2026 · 9 min lezen
Hoe AI-projecten echt in productie geraken (en waarom dat bijna niet gebeurt)
Je hebt een werkend experiment. Production is anders. Data is smerig, fallback ontbreekt, integratiewerk vergeten. Hoe zet je het goed op.

Je hebt het AI-experiment gedaan. Het werkt. Je wilt het inzetten. Dan gebeurt iets: het project stikt vast.
Niet omdat AI slecht is. Maar omdat productie heel anders is dan experiment.
Experiment vs productie
Experiment:
- 50 test cases
- Iemand babysit het
- "Goed genoeg voor prototype"
- Één persoon weet hoe het werkt
Productie:
- 50.000 cases per maand
- Werkt 24/7 zonder toezicht
- Moet failover-logica hebben
- Team moet het kunnen draaien zonder originele maker
Dit zijn hele andere beesten.
Waarom het stekt vast
Vier redenen, telkens:
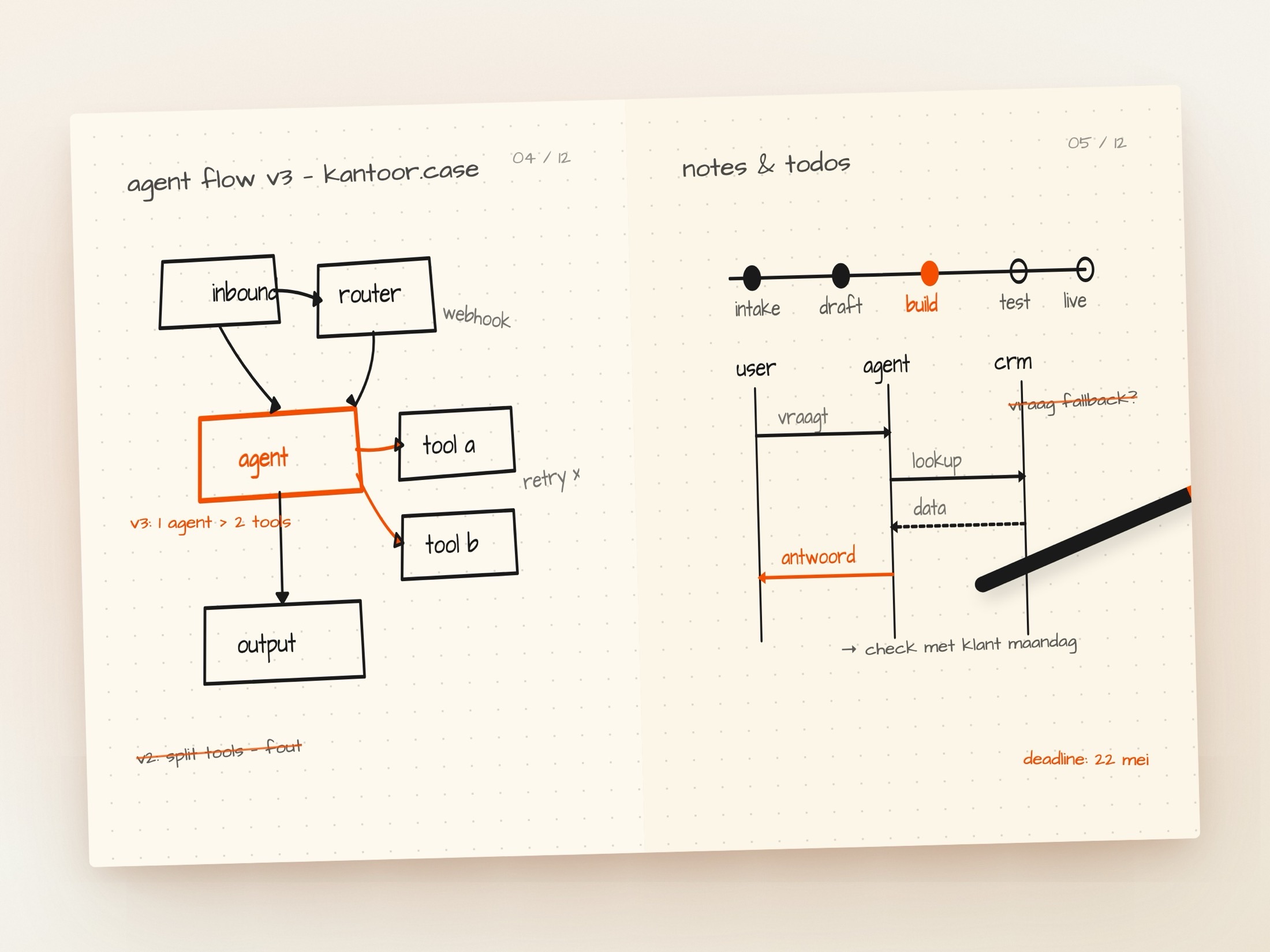
1. Fallback-logica bestaat niet
Je experiment: 100 emails groeperen naar type. AI haalt er 92% uit.
Production vraag: en de andere 8%?
- Automatic retry met ander model
- Escalatie naar medewerker
- Log error, parse later met ander systeem
Dit is 60% van het werk. Niemand budgetteert ervoor.
2. Data flow is niet echt
Je zet de AI in op "echte" data. Maar het dataset van je test is curated. Production data is smerig.
- Encoding issues (je hebt accenten niet aan zien komen)
- Duplicates (dezelfde data twee keer in je database)
- Missing fields (soms is kolom X leeg)
- Format-variaties (datum is soms DD/MM, soms MM/DD)
Je AI werkt perfect op je test, en breekt op dag 1 in productie.
3. Integratiewerk verdwijnt in het niets
Experiment: je hebt output in JSON.
Productie: output moet in Salesforce, emailen naar klant, en in data-warehouse.
Elk van die koppelingen:
- API key rotatie
- Error handling als API sloopt
- Data-transformatie naar elk systeem
- Testing per systeem
Dit wordt 30-40% van je project-tijd.
4. Monitoring is secondair, moet prioritair zijn
Experiment: je werkt het elke dag met elkaar door.
Productie: het werkt 3 maanden goed, dan gaat het langzaam slecht (model-drift, data-shift).
Je weet niet eens dat het slecht gaat. Totdat een manager 100 fout-verwerkte ordertjes ziet.
Monitoring moet van dag 1 zijn, niet week 8.
Stappen die het verschil maken
Als je AI in productie wilt:
Stap 1: Data-prep serieus nemen (week 1-2)
Niet "we hebben CSV". Maar:
- Je haalt 500 samples
- Je maakt ze schoon
- Je zet in je test
- Pas dan test je AI
Verwacht 20-40% van je data-work hier.
Stap 2: Fallback-logica eerste, niet laatste
Ontwerp dit voordat je de AI bouwt:
"Als AI confidence < 0.7: escaleer naar medewerker. Als API sloopt: herprobeert in 5 minuten. Als alles sloopt: log en handmatig door op dag 1."
Dit bepaalt je hele architecture.
Stap 3: Integratieplan per week
Week 1: AI werkt in test Week 2: Output naar 1 extern systeem (Salesforce) Week 3: Output naar 2e systeem (mail) Week 4: Data-warehouse sync
Niet "en dan integreren we alles tegelijk" op week 7.
Stap 4: Monitoring van week 1
Deploy monitoring parallel aan AI-bouw:
- Hoeveel cases per dag?
- Hoeveel fail met welke error?
- Accuracy op live data (spot-check)
- API response-time trends
Dit geeft je waarschuwing weken voor iets fout gaat.
Stap 5: Handover protocol
Week 1-8: jij bouwt. Week 9: overdracht.
Overdracht is niet "hier is de code". Maar:
- Team-training 2 sessies
- Runbook: hoe herstart je het?
- Escalatie-flow: waar gaat data heen als het niet werkt?
- Maintenance-kalender: wanneer update je modellen?
Zonder dit werkt het misschien 2 maanden, dan breekt het.
Eerlijke timeline
1-2 persoon AI project, productie-ready:
- Concept & data-prep: 2 weken
- AI-model bouwen & testen: 4 weken
- Integraties bouwen: 3 weken
- Monitoring & fallback: 2 weken
- Testing & fixes: 2 weken
- Documentatie & overdracht: 1 week
Totaal: 14 weken. 3,5 maanden.
Niet 2 weken. Niet "eventjes die API koppelingen". 3,5 maanden realistisch.
Als je sneller gaat: je slaat stappen over. Dan breekt het in productie.
Waarom veel projecten mislukken
Ze beginnen met AI-hype. Ze willen snel resultaat. Ze versnellen. Dan slagen fallback-, integratie- en monitoring-stappen ergens in het duister weg.
En dan: "AI werkt niet voor ons."
AI werkt. Maar productie is harder dan experiment.
Tags: AI, deployment, productie, implementation, fallback...